|
本文转载自微信公众号「飞天小牛肉」,作家小牛肉 。转载本文请关连飞天小牛肉公众号。 博彩平台游戏资讯口试最怕遭逢的问题是什么,怎样作念优化一定当仁不让,SQL 优化更是首当其冲,这里先跟大家共享一个比较容易清楚的 join 语句的优化~ 前文提到过,当莽撞用上被运转表的索引的技巧,使用的是 Index Nested-Loop Join 算法,这时性能照旧很好的;关联词,用不上被运转表的索引的技巧,使用的 Block Nested-Loop Join 算法性能就差多了,荒芜消耗资源。 皇冠体育针对 join 语句的这两种情况,其实都照旧存在不绝优化的空间的 老章程,背诵版在文末。点击阅读原文不错直达我收录整理的各大厂口试真题 Multi-Range Read 优化咱们先来总结一下 “回表” 这个倡导。回表是指,InnoDB 在平方索引上查到主键 id 的值后,再把柄主键 id 的值到主键索引树上去查询整行记载的过程。 那么,想考一个问题,回表的过程是一滑行地查数据,照旧批量地查数据? 昭着是一滑行地。 因为回表查询的本色即是查询 B+ 树,在这棵树上,每次只可把柄一个主键 id 查到一滑数据。 看底下这条语句,从 user 表中得回 80 岁以上用户的信息: 
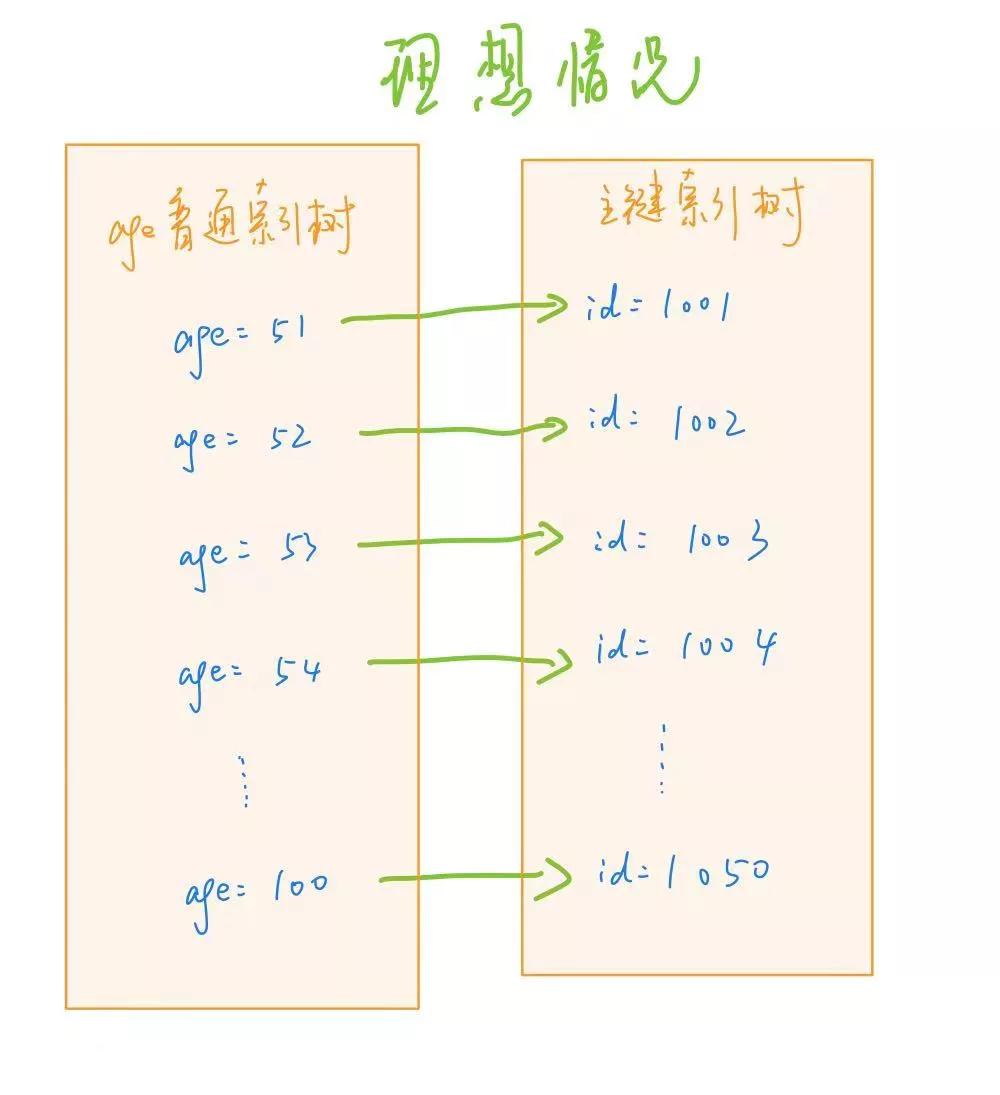
select 6868电子游戏* from user where age >= 80; 假定,age 对应的 id 是蚁集自增的,这么,咱们关于主键索引树的查询,即是蚁集的:
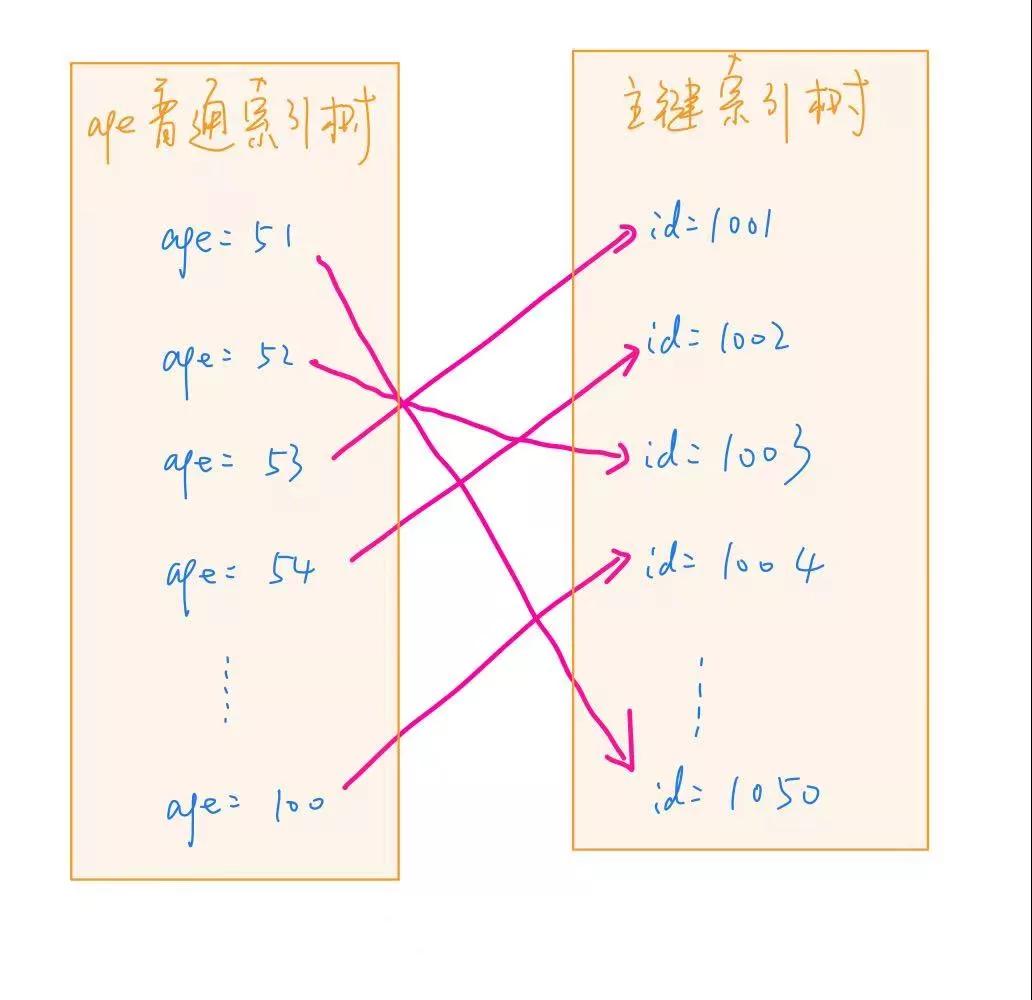
固然,这是逸想情况,淌若 age 对应的 id 值不是轨则的话,那当咱们轨则取 age 的技巧,id 的得回即是乱序马上的了,性能就会比较差。表现下为什么这里乱序查询的性能就比较差: 率先,咱们都知说念,索引文献其实即是一个磁盘文献,尽管有内存中 Buffer Pool 的存在不错减少探望磁盘的次数,关联词并弗成王人备遁入对磁盘的探望。而关于磁盘来说,一个磁盘从内到外有许多磁说念,一个磁说念又被分辨红多个调换的扇区,马上读取性能较差的原因即是每次都需要花消时辰去寻找磁说念,找到磁说念之后又要去寻找符合的扇区,从而浮滥多数时辰。是以轨则读取比马上读取快好多。
是以,一个很当然的想法,即是调理主键 id 查询的轨则,使其接近轨则读取,从而达到加快的策画。 那么,具体该怎样调理主键 id 查询的轨则呢?
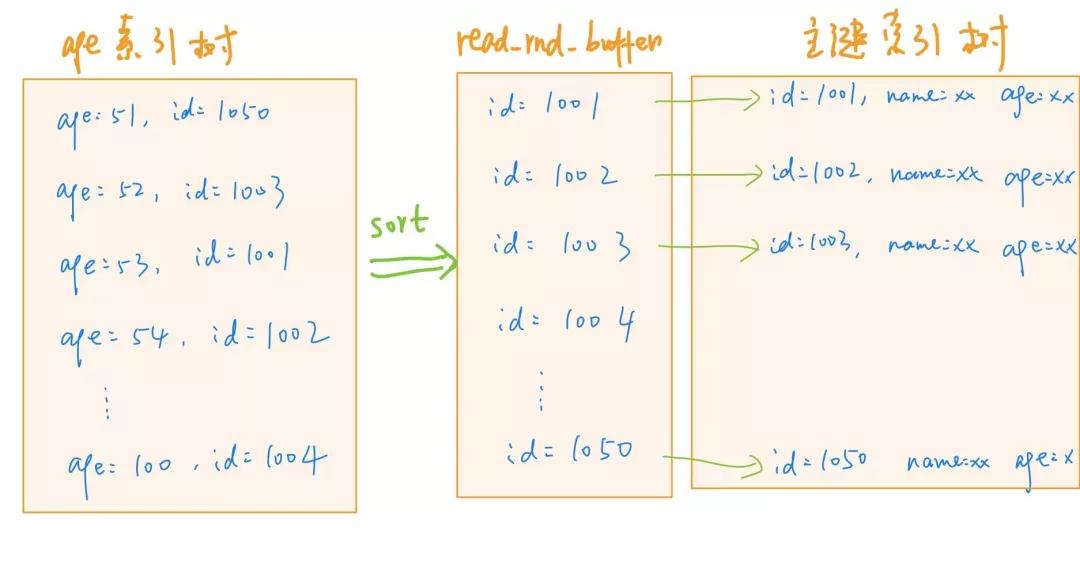
该负责人还表示:最近前线乌克兰部队的活跃程度明显增加,乌军很有可能在最近发起猛烈地反攻,外界国际社会和媒体也都猜测,乌克兰反攻或将在夏季结束后打响。 因为大多数的数据都是按照主键 id 递加轨则插入的,对吧,是以咱们不错浅近的以为,淌若按照主键 id 的递加轨则查询的话,对磁盘的读取会比较接近轨则读取,从而擢升读性能。这即是 Multi-Range Read (MRR) 优化的想想。 皇冠博彩而将主键 id 进行升序排序的过程,是在内存中的马上读取缓冲区 read_rnd_buffer 中进行的。 咱们不错树立 set optimizer_switch="mrr_cost_based=off" 来开启 MRR 优化,这么,语句的引申过程即是底下这个款式: 把柄平方索引 age,找到满足条款的主键 id,然后将 id 值放入 read_rnd_buffer 中 将 read_rnd_buffer 中的 id 进行递加排序; 把柄排序后的 id 数组,进行回表查询
需要致密的是,read_rnd_buffer 的大小是由 read_rnd_buffer_size 参数放弃的。淌若发现 read_rnd_buffer 放满了,那么 MySQL 就会先引申完门径 2 和 3,然后清空 read_rnd_buffer,之后再不绝轮回。 不错看出来,使用 MRR 擢升性能主要适用于限制查询,这么不错得到充足多的主键 id,通过排序以后,再去主键索引查数据,从而体现出轨则读取的上风。 MRR 这种开采一个内存空间对主键 id 进行排序的想想呢,诓骗到 join 语句的优化层面上来,即是 MySQL 在 5.6 版块后引入的 Batched Key Access 算法(BKA),底下咱们来瓦解下这个算法以及怎样使用这个算法对 Index Nested-Loop Join 和 Block Nested-Loop Join 两种情况进行优化。 优化 Index Nested-Loop Join假定咱们照旧在 age 字段上成立了索引,那么底下这条 sql 语句用到的即是 Index Nested-Loop Join 算法,总结下具体的引申逻辑: select * from table1 join table2 on table1.age = table2.age where table2.age >= 80; 从 table1 表中读入一滑数据 R 从数据行 R 中,取出 age 字段到表 table2 的 age 索引树上去找并取得对应的主键 把柄主键回表查询,取出 table2 表中满足条款的行,然后跟 R 构成一滑,欧博注册网址手脚效果集的一部分 也即是说,关于表 table2 来说,每次都是只匹配一个值。这时,MRR 的上风就用不上了。 是以,淌若想要享受到 MRR 带来的优化,就必须在被运转表 table2 上使用限制匹配,换句话说,咱们需要一次性地多传些值给表 table2。那么具体该奈何作念呢? 门径即是,从表 table1 中一次性地多拿些行出来,先放到一个临时内存中,然后再扫数传给表 table2。而这个临时内存不是别东说念主,即是 join_buffer! 之前咱们分析过 Block Nested-Loop Join 算法顶用到了 join_buffer,而 Index Nested-Loop Join 并没灵验到,这不,在优化这里派上用场了。 皇冠体育是哪个国家的这即是 BKA 算法对 Index Nested-Loop Join 的优化,不错通过底下这行号令启用 BKA 优化算法 set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; 前两个参数的作用是启用 MRR,因为 BKA 算法的优化依赖于 MRR。 优化 Block Nested-Loop Join那淌若用不上被运转表索引的话,使用的 BNL 算法性能是比较低的,是以常见的优化门径即是给被运转表的 join 字段加上索引。 关联词,淌若这条 SQL 语句的使用频率比较低况兼数据量不大的话,成立索引其实就比较毁坏资源了。 是以,有莫得一种两全其好意思的主义呢? 这技巧,咱们不错考虑使用临时表。使用临时表的大要想路是: 把表 table2 中满足条款的数据放在临时表 temp_table2 中 每个运动员都有自己的风格和特点,这也是他们获得成功的关键。给临时表 temp_table2 的字段 age 加上索引 让表 table1 和 temp_table2 作念 join 操作 这么,一个 BNL 算法的优化问题,就被咱们退换成了 Index-Nested Loop Join 的优化问题了,按照上述所说的,不错使用 BKA 进行优化。 具体的 SQL 语句如下: # select * from table1 join table2 on table1.age = table2.age where table2.age >= 80; create temporary table temp_table2 (id int primary key, name varchar, age int, index(age)) engine=innodb; insert into temp_table2 select * from table1 where age >= 80; select * from table1 join temp_table2 on (table1.b=temp_table2 .b); 总的来说,优化 Block Nested-Loop Join 的想路即是使用有索引的临时表,让 join 语句莽撞用上被运转表上的索引,从而退换为 Index Nested-Loop Join 然后触发 BKA 算法,擢升查询性能。 终末放上这说念题的背诵版: 口试官:SQL 优化了解过吗? 小牛肉:先说 join 语句的优化 皇冠篮球走地比分join 语句分为两种情况,一种是莽撞用上被运转表的索引,这个技巧使用的算法是 Index Nested-Loop,另一种是用不上,这个技巧使用的算法是 Block Nested-Loop 关于 Index Nested-Loop 来说,具体门径其实即是一个嵌套查询,率先,遍历运转表,然后,对这每一滑都去被运转表中把柄 on 条款字段进行搜索,由于被运转表上成立了条款字段的索引,是以每次搜索只需要在扶持索引树上扫描一滑就行了,性能比较高 关于 Block Nested-Loop 来说,MySQL 率先把运转表中的数据读入线程内存 join_buffer 中;然后扫描被运转表,把被运转表中的每一滑按序取出来,跟 join_buffer 中的数据作念对比,满足 on 条款的,就手脚效果集的一部分复返。BNL 算法的性能比较差,因为咱们需要屡次遍历被运转表。那么关于 BNL 算法来说,一个很常见的优化想路即是对被运转表的条款字段成立索引,从而退换成 Index Nested-Loop 算法。关于上头这两种 join 情况来说,淌若不绝添加一个限制查询的 where 条款的话,其实还存在优化空间。 uG环球捕鱼其中枢作念法其实即是针对限制查询的优化,也称为 Multi-Range Read 算法 皇冠客服飞机:@seo3687具体来说,因为大多数的数据都是按照主键 id 递加轨则插入的嘛,是以咱们不错浅近的以为,淌若按照主键 id 的递加轨则进行查询的话,对磁盘的读取会比较接近轨则读取,这么比拟于乱序读取的话减少了寻说念时辰,从而擢升读性能。 而将主键 id 进行升序排序的过程,是在内存中的马上读取缓冲区 read_rnd_buffer 中进行的。即是先把在扶持索引树上查找的满足条款的主键 id 存到 read_rnd_buffer 中,然后对这些 id 进行递加排序,把柄排序后的 id 数组,进行回表查询。 MRR 的想想诓骗到 join 语句的优化层面上来,即是 MySQL 在 5.6 版块后引入的 Batched Key Access,BKA 算法 关于 Index Nested-Loop 来说,即是一次性地从运转表中取出好多个行记载出来,先放到临时内存 join_buffer 中,然后再扫数传给被运转表 关于 Block Nested-Loop 来说,即是对被运转表成立一个临时表,况兼对条款字段成立索引,然后把之前两张表的 join 操作退换成运转表和临时表的 join 操作,从而退换成对 Index Nested-Loop 的优化问题
balabala.......(后续其他 SQL 优化会逐步更新的~)
|